
画像生成AIを使っていると、なかなか思うような画像にならなくて、だんだんAIも自分もカオス状態に陥った経験はありませんか?
そんな画像生成AIのプロンプト、特にMidjouneyに特化して重要なポイントを解説します。
わたしは、2023年1月からMidjouneyを使い倒しているハードユーザーです。
Midjouneyのプロンプトの基礎から裏技まで、わたしが得た知識を大放出します。
この記事を読めば、プロンプトの魔術にかかってモヤモヤすることがなくなります。
では、さっそくプロンプトのコツをご紹介しましょう!
【Midjouneyの初心者向けはこちらから】

Midjouneyプロンプト基本の構成
Midjouneyのプロントの基本の構成は、下図のようになります。
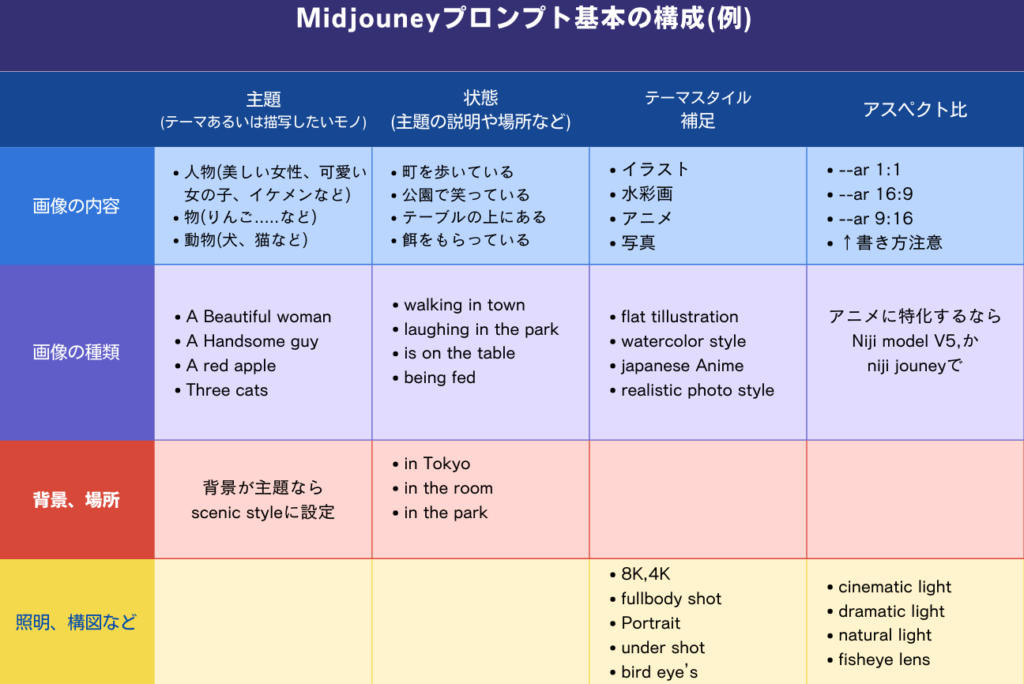
「主題(テーマあるいは描写したいモノ) + 状態(主題の説明や場所など) + テーマスタイル+アスペクト比」
文章の区切りは、半角でコンマ+半角スペースで区切るようにしてください。
例文/ a horse and horse drawn caravan, door on the side, forest background, anime–ar 16:9
①AIに一番伝えたいテーマを1番先頭に(男性、女性、こども、動物、物)
②それがどんな状態か(どんな髪、服装、表情)
③どこにいるか
④画風や照明、アングル
⑥画像のアスペクト比
(ハイフォン、ハイフォン、ar、半角スペース、16:9)
例文の日本語訳/ 馬と馬が引くキャラバン、側面の扉、森の背景、アニメ –ar 16:9

この順番がプロントの基本的な構造です。
上手に主題を伝えるコツ
まず、AIに描いて欲しい内容を正確に伝えることが大切です。
プロンプトの長さについて
プロンプトは短いほうがいいと主張している人もいますが、一度出力した画像に「こうじゃないんだよな」と詳しい指示を加筆しているうちに長くなります。
AIが混乱するのが問題なのであって、長いとか短いとかは問題ではありません。
AIが混乱しない良いプロントが書ければいいわけです。
AIを混乱させないために
よけいな言葉や重複した言葉、相反する言葉は、AIが混乱するので好ましくありません。
AIが混乱する原因は主に、
- 人物や服装髪型背景色柄ライティングなどに対して細かい指示を出していない
- 画質の良さに関する指示が甘い
- プロンプトに対して正確ではない絵でもダウンロードしてしまう
上記が何故いけないかというと、プロンプトに対して間違った絵でもAIは「気に入ってくれた!これは正しいんだ」と認識してしまうからです。
「プロンプトとは違うけれどもこれはこれでアリかも」と思っても、じっと我慢です。
作業が終わってから、後日ダウンロードしてください。
あいまいな表現は通じない
「多数の」「何人かが」「いくつかの」は、文章を読んでいるのが人間ならば、
だいたい100ぐらい、2~3人、2~3個、と想像できますが、AIはそれができません。
AIは数が何個まで数えられるのかわかりませんが、
「6個の枕が山積みになって」これだけで多量の枕が出現します。圧死するほど。

6個ならば山積みはやめたほうがいいです。
ひとりの女性を描きたいなら、aをつけましょう。英語圏ではあたりまえなことが、日本人は省略します。
今のところ、主題に3人以上は苦手なようです。背景ならなんとかいけます。
そのうちに、バージョンアップして賢くなるでしょう。
例:〈伯爵である父親と令嬢の食事している様子〉

1番と4番は3人になっています。
上手に状態を伝えるコツ
プロンプトを機能させるには「必要な単語」を「決められた順番で書くこと」が大事です。
状態を伝えるのは意外と難しい
状態を表すプロンプトをAIが一発で正解してくることはあまりありません。
4枚の画像のうちどれもダメだったら、修正をあきらめて、新しくプロンプトを作った方が早いです。

状態ってどういうこと?
「走っている」「声に出して笑っている」「口元に手を当ててあくびしている」などなど

出来るだけ具体的に、何を描いて欲しいか伝えることです。
たとえば、「笑っている」でもsmiling なのか laughing なのかで状態は変わります。
新しくプロンプトで生成した4枚で、1枚正解していたら、その絵にバリエーションをかけるか (成功率は低い)、アップスケールしてMidjouneyの新しい機能を利用すると簡単に修正できます。
それは、Vary(Region)です。
Version 5.2で使える神業紹介
Version 5,2で「惜しい!ここがこうならいいのに」という絵が出たら、Vary(Region)。
この神業を使います。それは、超簡単です。
Vary(Region)を利用するためには、/setting で設定します。
- Version 5.2に設定
- Remix mode を設定
作例:餌付けされてる犬の片目が見えにくい、片目が描いていないと誤解されそうなので、もうちょっと目を描いて欲しいな。

修正したい絵をアップスケールすると、下図のような画面になります。
そこで、Vary(Region)を選択します。
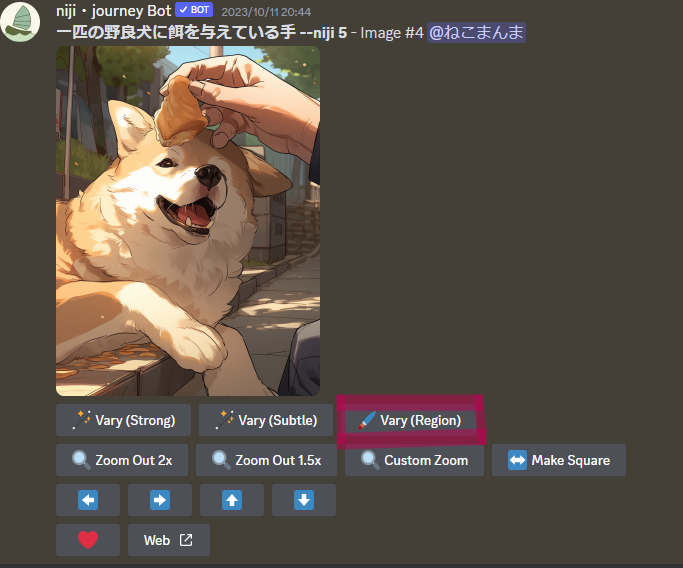
修正して欲しい箇所を、四角か円で塗りつぶします。
このとき、少しおおきめに塗りつぶすのがコツです。
プロンプト記入欄には、eye とだけ入れます。
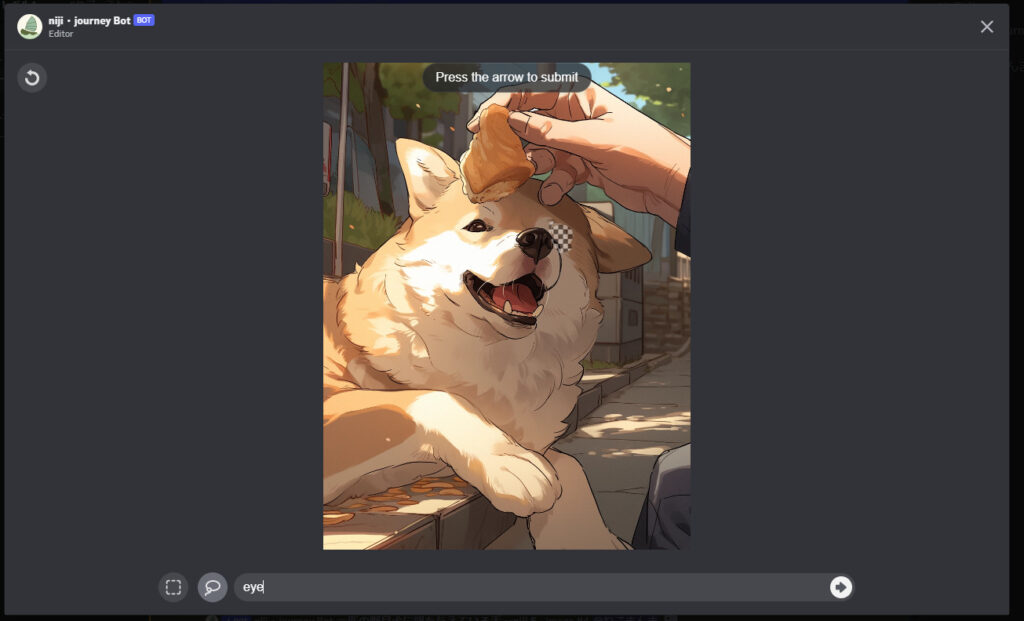
かわいいお目目ちゃんが、ハッキリと描かれました。

背景や画風はどこに入れるか

主題の書き方はわかった。じゃ、背景とか画風はどうすればいいの?
基本的には後ろの方です

基本的にということは、例外があるのかな?
はい、ではそれについて説明しましょう
背景が重視ならモードを変える
niji journey を使っていて主題が背景の場合は、モードをscenic styleに設定します。すると風景重視になります。
Midjouneyで主題が人物で背景は…という補足なら、プロンプトの後ろの方に入れます。


↑ デフォルトで背景をプロンプトの後ろに書いた場合
↑ モードをscenic styleにして、背景をプロンプトの後ろに書いた場合
基本的にはプロントの最後の方
風景画ではない場合、AIが人物は主題で、これは補足事項なんだなと理解させる必要があります。
そのために、主題を正確に伝えるには、順番が大切なのです。
一番最初に背景を指定するケース
では、例外はどのようなときでしょう。
それは、一度出してきた絵に、バリエーションをかける時です。
元のプロンプトの冒頭に、改めて背景や画風を書き込みます。
意際に、森の中を通る馬車で試してみましょう。

3番の絵にバリエーションかけてみます。
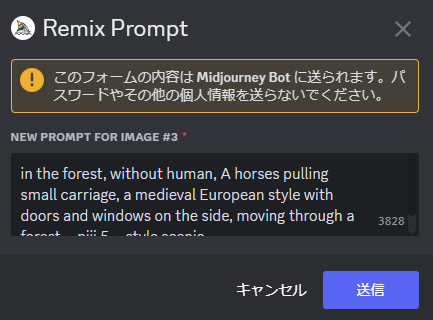
元のプロンプトの冒頭に、「in the forest 」と入れました。すると・・・・

森の中を通っている状態の絵になりました。
このように、AIは元画像はあっているけど先頭の単語にしたいんだなと理解してくれるのです。
修正するときも、一番伝えたい言葉は先頭にする。
これがコツです。
照明やアングルを上手に伝えるコツ
一眼レフカメラを持っていないと知らないような言葉を、プロンプトに使うとAIには効果的です。
AIが学習するときに写真集などを用いたのかもしれません。
よく使うプロンプト
照明やアングルに関する用語は、たくさんありますが、わたしがよく使うプロンプトを紹介しましょう。
↓ 自然な光ーーーーーーーーnatural lighting

↓ やわらかい照明ーーーーーsoft lighting

↓ 映画のような照明ーーーーーcinema lighting

↓ ドラマティックな照明ーーーdramatech lighting

↓ 下からのアングルーーーーーlow angle

↓ 上からのアングルーーーーーhigh angle

↓ 鳥の目線でーーーーーーーーーbird’s eye

逆光に負けないで
照明について特に何も指示しないと、逆光になることがよくあります。
特に気にならなければいいのですが、気になって夜も眠れないようならバリエーションで修正をかけてみてください。
あまり、気にしすぎると何枚も出してしまい、まるでAIの魔術にかかったように出力し続けることになりますから、ご注意ください。
ネガティブプロンプトだけに頼らない
ネガティブプロンプトとは、出してほしくないものを no 〇〇〇と指定するプロンプトです。
Midjouneyではあまり使いません。
使っても必ず出力されないという保証もありません。
特に、niji jouneyでは高い確率で女の子や不思議な生物が出現します。
AIの癖をよく知ったうえで、使うといいでしょう。
Version 5,2で使える神業で消す方法
これは、私が出力した絵です。

「メガネが要らないなー」こんなときは、Vary(Region)を使います。
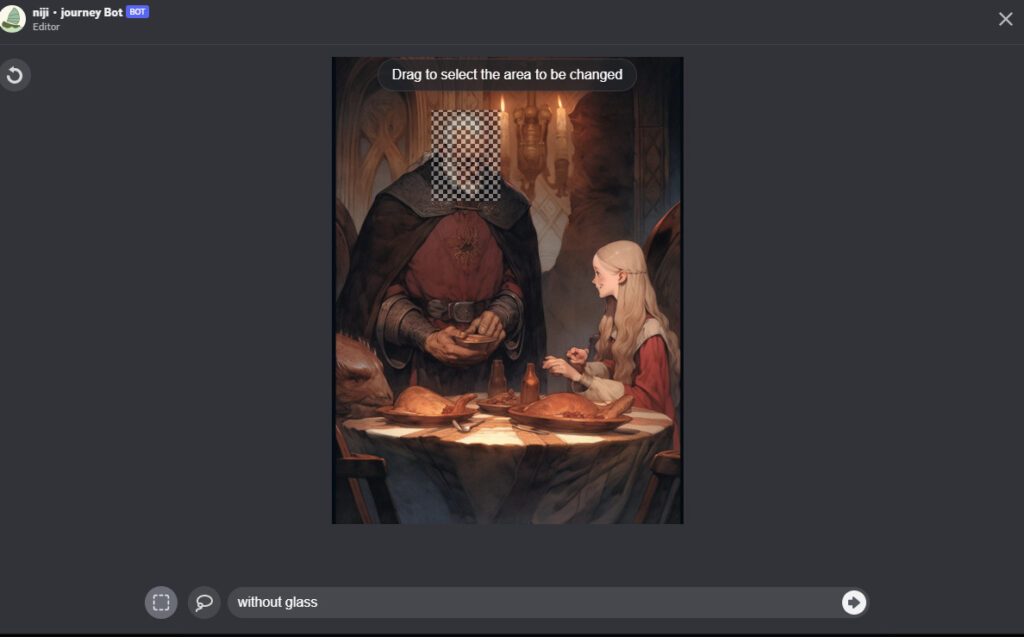
消したい部分を塗りつぶして、「without glass 」と入力します。

これでメガネが消えました。
Vary(Region)を使えば、ほかの画像が崩れることなく必要な部分だけ消すことができます。
今までは、バリエーションにネガティブプロンプトを入れても、消えなかったり絵が崩壊したりして何枚も何十枚も絵を出さし続けていたのに、
Vary(Region)なら一発で欲しい絵が出ます。
こんなのが欲しかった、ですよね。
/describeを上手に利用する方法
describeは、描きたい画像の参考画像を投入して画像を生成する方法です。

それだけでいいの?プロンプト書かなくていいから楽勝じゃん
と、思ったあなた、それは大きな間違いです。
私も最初は楽でいいじゃんと思っていました。
しかし、describeで成功したことはありません。
なぜでしょうか。
それは、画像を読み取ってAIが作ったプロンプトには不備があるからです。
たいてい/describeは失敗する
Describeでは4つのプロンプトが出てきます。
英語のプロンプトの内容をよく確かめもせずに、全部クリエイトボタン押していませんか?
英語が達者な方なら、おわかりいただけると思いますが、元画像に正確なプロンプトではありません。
嘘だと思ったら、describeのプロントを Google翻訳にコピペしてみてください。
どうですか?元画像に忠実ですか?
Describeで出てきたプロンプトは破綻しています。
/describeで失敗しないための裏技
実際にやってみましょう。
/describe で作りたい絵のイメージ画像を貼り付けます。
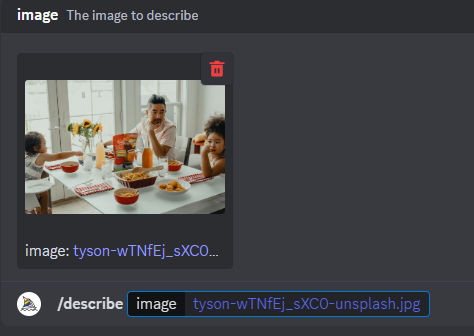
AIが出してきたプロントです。

4つのプロントをすべて生成してみると・・・・




ひどいもんです。
この中から、一番イメージに近いのは3番目ですね。
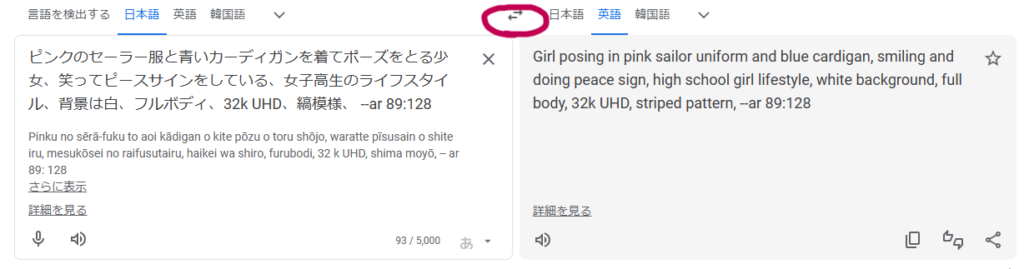
3番目のプロントをGooble翻訳に入れてみましょう。
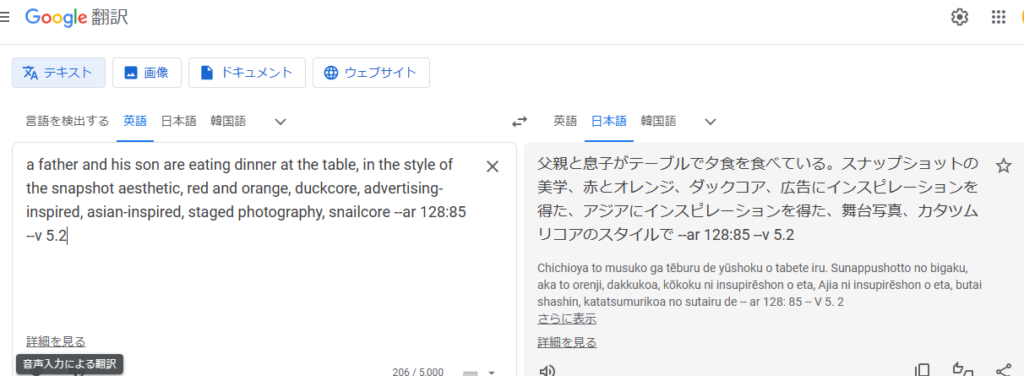
翻訳してみると、要らない単語、間違った表現がありますね。
これを→と←重なっているマークをクリックすると、英語と日本語が逆になります。
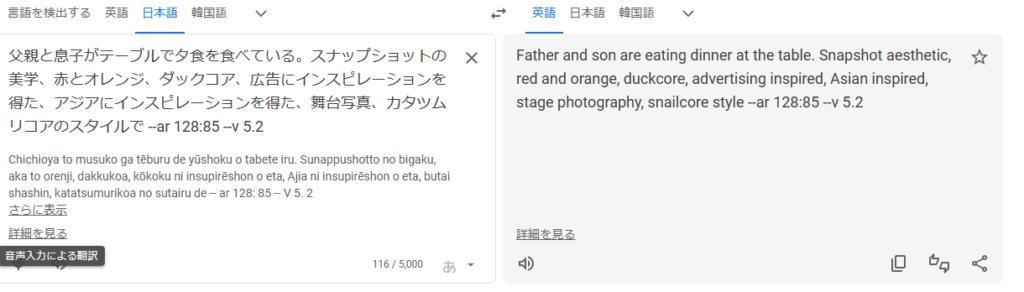
これで日本語の部分を修正していきます。
わたしが作った日本語版が下図です。
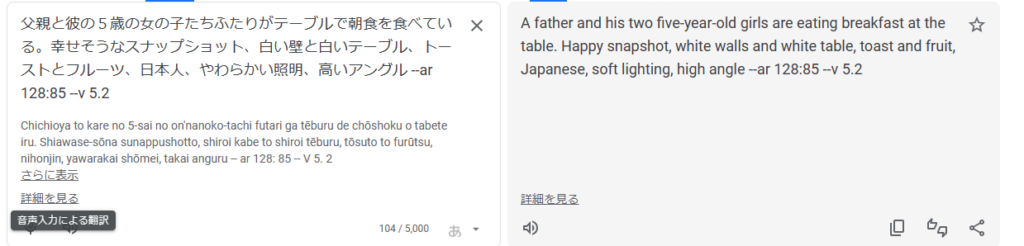
これで生成してみましょう。

いかがでしょうか?
元画像に近いイメージで生成できたと思いませんか?
もう一つやってみましょう。
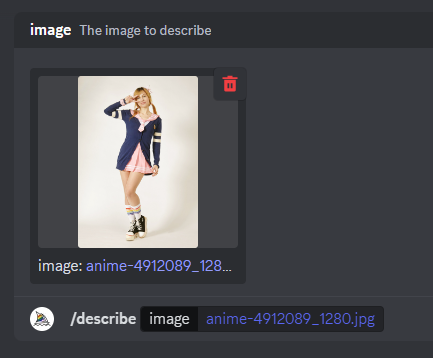
これは単純だからいけるかな。
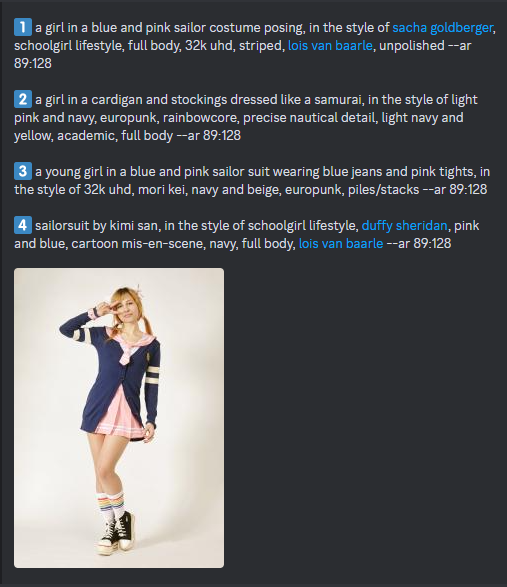
一番目がこれです。

プロントをGooble翻訳に入れて
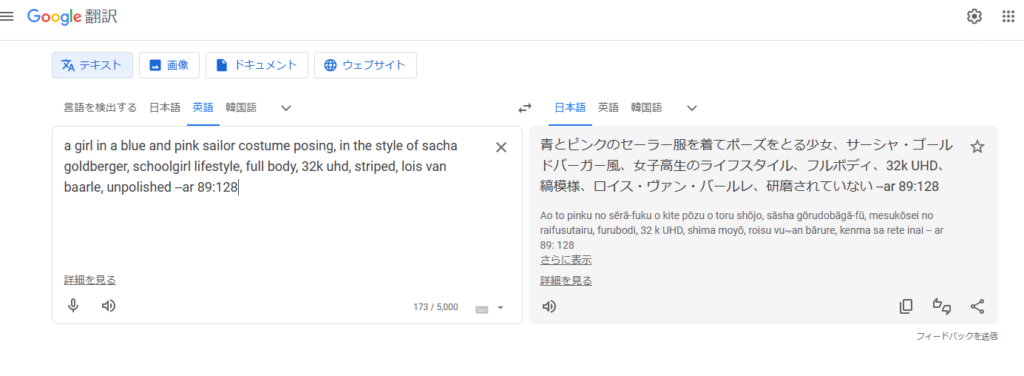
日本語と英語を逆にして、日本語を修正します。

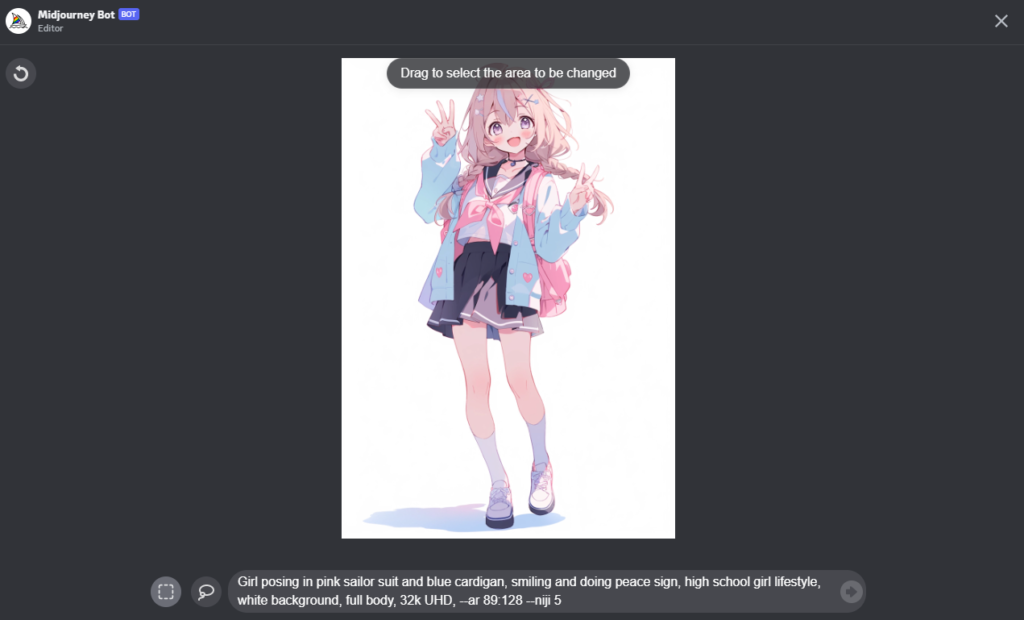
男の子が出たり、脚が3本なったりしてますが、右側はまあまあですね。
セーラー服という概念は日本と違うので、アニメにしたほうがセーラー服が出ると思います。
やってみましょう。

4番目が全身入っていていいのだけれど、ピースサインが指3本です。
惜しいミスなので、こういう時はVary(Region)を使いましょう。
元のプロントは消して、peace sign とだけ入力します。
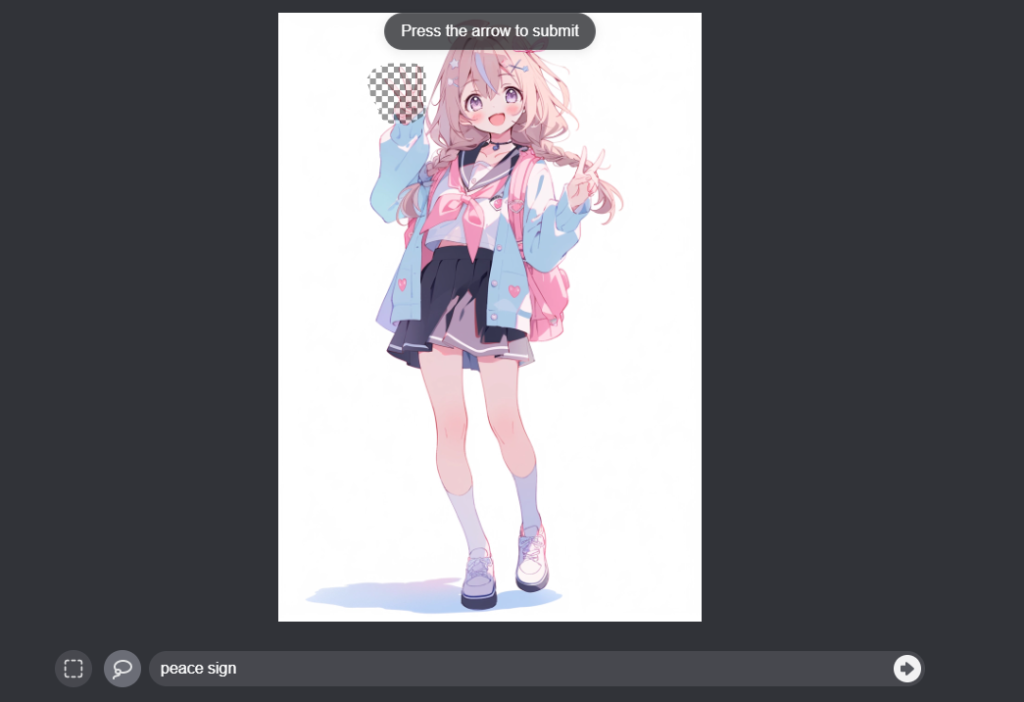
完成!

おさらいです。
- Describeで出てきたプロンプトをGoogle翻訳にコピペし
- 英語と日本語を左右逆にする
- 日本語でこれは不要だと思われるぶぶんを削除
- 元画像に近づくように日本語を修正
- 修正された英語を/imagineにコピペしてEnter
これで、修正したい箇所が見つかったら、Vary(Region)です。
これでかなり元画像に近づきます。
こんなに手間がかかるんだったら、describeしないで最初からプロント作ればはやいんでね?
その通りです。
しかし、Describeで出てきたプロンプトを調べることで、英語とプロンプトの勉強にはなります。
根気が要る作業ですが、無駄にはなりません。
AIにプロンプトを理解してもらうコツ
どうしたらAIが人間の作ったプロンプトを理解してくれるのでしょうか。
これにも、コツがあります。
根気よく何枚も出してもカオスになるだけ
「AIはガチャみたいなもので、何回かやっていれば運よくいい画像が出る」と思って、同じプロンプトで何回も出してしまう気持ちはわかります。
そのとき、4枚の絵の中から気に入った絵だからという理由で選んでいませんか?
AIに人間の意図を伝えるには、それをやったら失敗です。
コツは、気に入ったからではなく「プロンプトの意味に合っている」「わたしが期待している絵」だけをアップスケールすることです。
AIは「こういう絵が好きでしょう」と言わんばかりにプロンプト無視で画像を出すときがあります。
おそらく、今までプロンプトで要求された傾向を分析してるのだと思います。
「プロンプトの意味と違うけど、これいいわ」と手をだしたら、AIは「この絵がお気に入りなんだね」と延々とその路線で出してきます。
一度手を出してしまってから「そうじゃない、そうじゃなくてこう」といったところで、AIは「さっきと違うこと言ってくるな」と混乱します。
そうなったら、もうカオスです。
それともうひとつ、エロ画像や有名な企業の名前を入れたデザインなど、法に触れる可能性があるものは、崩壊した画像を出してきます。
この場合も、何枚もだしたところでカオス状態に陥ります。
カオスに陥ってしまった例がこちらです。

AIが学習してきたであろう画像を想像して指定する裏技
AIはいろんな画像を学習してきています。
その学習してきているであろう画像を予想してプロンプトに入れると、一番思い通りの絵がでてきます。
有名人の顔は肖像権侵害にあたるのでNGです。
けれども、画風を指定するのは問題ないのではないかと。(個人的意見)
人間が絵を学ぶときも、すきな画家や写真家などの作風に影響を受けるものです。
人間が描いた絵が○○に画風が似ているからダメとはならないのと同じではないでしょうか。
実際、/describe でAIが出してきたプロンプトをみると、アーティスト名が複数入っています。
(アーティスト名を複数入れると、個性的な作品に仕上がります。)
しかし、最新のDALL-E 3ではChatGPTがプロンプトをつくるので、アーティスト名が入ったものははじかれてしまいます。
英語で映画の作品名を入れたら、その映画風の絵は生成できました。
日本語はダメでした。この話はまた後日。
まとめ
画像生成AIは一発で思い通りの絵が描けるものではありません。
けれども、プロンプトの構造やAIの癖を見抜けば、誰にでもいい絵が描けます。
その過程を楽しむことができるかできないかが、上達の分かれ道です。
わたしはMidjouneyを使い倒しているのでその癖を理解したうえで、Midjourneyで使えるプロンプトについて解説させていただきました。
使いこなそうと試行錯誤してるうちに、だんだんハマってしまったのです。
あなたもハマりすぎに注意してくださいね。
